C++ | 右值引用 & 移动语义
这是 cpp 网课学习笔记
左值和右值
引入
考虑这样一段代码
int n; |
对于这段代码, 我们不难理解这是错误, 但是当我们思考错误的原因, 可以发现这并不简单
为什么 1 = n; 会报错而 n = 1; 却是合法的呢?
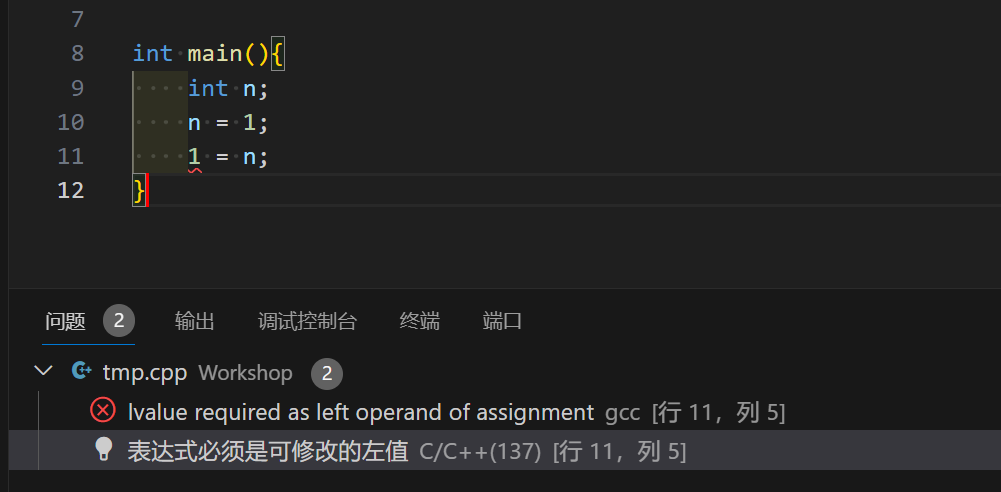
观察编译器给出的报错提示 表达式必须是可修改的左值, 一个全新的概念出现了–左值(lvalue)
表达式的值的类型
与 1 = n; 类似的语句还有很多, 例如 int foo(); foo() = 3;, int m; m + 3 = 4; 等等, 这些语句的出现似乎在提示我们一个很简单的道理, 一个你的 C 语言启蒙老师大概率和你讲过的话:
C 语言里面的表达式不是方程
正因如此, 我们就能理解下面这句话了
即便变量类型相同, 依然存在某些表达式是不能被赋值的
那么那些无法赋值的表达式到底有什么特征呢?
很简单, n 表征一个对象, 在物理意义上表征着内存中的某一块; 而 1 不表征一个实在的对象, 也就是说, 他表征着一个不与对象关联的值, 也就是字面量
回到形如 foo() = 3;, m + 3 = 4; 的语句, 套用我们刚才的分析, 可以发现, 不论是 foo() 还是 m + 3, 他们这个表达式所返回的值都是临时的, 不表征任何一个对象, 不关联任何一片内存, 因此尝试对其赋值的操作是不合法的
由此, 假如我们改变 foo() 的定义, 让他返回一个不临时的变量, 是不是就可以对其赋值呢?
答案是肯定的, 请看如下实例
int n; |
实际上, 在 C++ 中, 我们严格区分了可以赋值的表达式与不可赋值的表达式, 也就是说, 一个表达式有如下两个属性:
- type
- value category
- lvalue: 表征一个具体的对象 / 一块确定的内存
- rvalue: 不与对象关联
当然, 要区分的是, 这个 value category 所表示的是表达式的值的性质, 而不是值的性质
左右值的内存使用
那为什么我们一定要引入左值和右值的概念呢? 实际上如果我们从汇编的角度来看, 可以发现假如我们只有左值(当然不能只有右值, 因为你也不想你的语言无法赋值吧), 我们就要为每一个表达式都分配一个寄存器进行内存操作, 这大大提高了 C 语言向汇编编译的复杂度, 对效率是极其不利的
不过我们也不能绝对的说右值就不能占用内存, 有的时候, 右值也是可以占用内存的
与之类似的是, 左值表征了一个对象, 从概念上来说左值一定要占用内存, 但是有趣的是, 有的编译器会对一些比较简单的情况做出优化, 这时候左值就不占用内存了
例如
int foo(){ |
foo(): |
这样的优化一般只发生在我们注意不到的前提下
请忘记这一点, 让我们暂时记住左值一定占用内存
左值
lvalue 表征一个具体的对象 / 一块确定的内存, 支持取地址 & 和初始化引用操作
不是所有的左值都支持赋值
例如 const char name[] = "Vanadium"; name = "Vagrant"; 就是非法的, 之所以 name 不能被赋值, 不是因为他是特殊的左值, 而是因为他是 const value 常量
那左值具体包含什么呢?
- 任何有名字的表达式一定是左值 (枚举除外)
- 内置的
++a,a = b,a += b,(他们的返回都是对变量的引用)*p,p->m(他们一定占用内存) 是左值 - 如果
a[n]的操作数之一的佐治数组或指针 - 对左值结构体作成员访问
- 强制类型转换为引用
- 字符串字面量(const char[N])
其他字面量都是右值
当左值放在赋值表达式的右边时, 则会发生左值向右值的隐式类型转换
右值
rvalue 并不表征一个对象, 非左值的表达式即是右值
右值表达式经常
- 用来计算内置运算符的一个操作数
- 例如
1 + 2 + 3中, 1 和 2 是右值, 1 + 2 也是右值
- 例如
- 初始化一个对象
- 例如
int i = 1 + 2;,int f(int); f(2);
- 例如
右值的举例
- 枚举数和除了字符串字面量以外的字面量
- 内置的
a++,a + b,a || b,a < b,&a等 - this
- lambda匿名函数
纯右值和将亡值
引入
对于 C++ 来说, 类和结构会对简单的左值和右值的区分造成困惑
考虑代码:
typedef struct{ |
根据我们在上一章节的讨论, Func()的返回值应该是一个右值, 他不表征一块具体的内存, 但是他又必须表征一块内存, 才能通过 . 访问字段 y
这样矛盾的表达式就带来了困惑
再考虑代码
const int & cr = 1; |
我们知道, 1 是一个右值, 执行上述赋值语句, 会创建一个临时变量以匹配左值的类型, 那么这个临时变量又从何而来?
当一个右值需要继续使用时, 它的生命周期会被自动延长, 相比于正常的右值, 这是一种既是临时的, 又占用内存的奇怪的右值
纯右值和将亡值
为了区分不同的右值, 我们引入纯右值 prvalue 和将亡值 xvalue
右值
- 纯右值
- 将亡值
纯右值和将亡值都是临时的, 但是将亡值在生命周期内, 会占用内存
有了分辨的手段, 我们可以深入研究右值
纯右值通常用来完成
- 计算内置运算符的一个操作数
- 初始化一个对象
int i = 1;Foo Func(); Foo f = Func();拷贝省略 copy elisionconst int & r = 1;纯右值向将亡值的隐式类型转换 / 临时物化 temporary materialization
拷贝省略和临时物化先做省略
同时我们可以从是否占用内存的角度, 将表达式分为占用内存的 glvalue(= lvalue + xvalue) 和不占内存的 prvalue 两种
- expression = glvalue + rvalue
- glvalue = lvalue + xvalue
- rvalue = xvalue + prvalue
| property | 左值 | 将亡值 | 纯右值 |
|---|---|---|---|
| 取地址 | T | F | F |
| 被赋值 | T(如果可修改) | F | F |
| 初始化引用 | T | 仅const& | 物化为将亡值 |
理论上将亡值占有内存的时候是可以取地址的, 然而它的生命周期实在是太短了, 指向它的指针最后还是指向一个未知的内存, 所以在 C++ 中, 这种操作是非法的
移动语义
移动语义引入
有些时候, 通过类来构造类并不会额外申请一块内存来复制构造, 会直接交换两个类的指针, 这样的构造方法, 我们称为移动语义 moving semantics
这样的构造方法, 可以节省内存的开销(学 C 人的执着可能就是这样了吧)
如下代码(省略多余代码)
template<typename T> |
假设 a 表征内存块 memory_1, 当我们执行
Container<int> a; |
时, 实际上发生的是构造函数 Container<int>() 返回了一个临时对象 c, 表征内存块 memory_2;
然后 a 与 c 相互交换所表征的内存块, 之后 c 的生命周期结束, 执行析构函数后删除 c 所表征的内存块, 但是要知道, c 现在表征的内存块不是储存了数据的 memory_2, 而是空空如也的 memory_1, 与此同时, a 所获得的也是有数据的 memory_2
这样可以理解为 a 从即将消亡的临时对象 c 那里获得了内存块
下一个问题是考虑 /* some type */ 是什么
但是分析过后, 以下都是不可行的
Container<T> &rvalue 不能绑定给非常量引用const Container<T> &无法修改成员Container<T> *rvalue 不能取址
难道真的没办法吗?
右值引用
为了解决问题, C++11 引入了右值引用 rvalue reference
对于类型 X, 称 X&& 为右值引用; 与此对应的 X& 被改称为左值引用
那么之前的函数可以写作
template<typename T> |
右值引用只能绑定右值, 举例
int z = 1; |
左值引用和右值引用在能做什么事情方面没有区别, 区别是什么值可以绑定给这个引用
移动语义实现移动构造函数
template<typename T> |
清晰了右值引用的概念, 我们对 临时 的理解就可以更加深刻了
所谓临时, 其实就是指资源是否可以复用
lvalue 不可复用, prvalue 需要物化后才能复用, xvalue 是可以复用的
同理, 我们可以用移动语义优化交换函数
template<class T> |
这样的写法通过强制类型转换把 a, b, tmp 的类型都转化为右值引用, 避免了编译器误解我们想要通过移动语义优化操作的本意
上述写法还可以优化
template<class T> |
相比直接使用强制类型转换, static_cast<> 有很多的优势
std::move 实现移动语义
为了便于表达意图, C++11 引入了 std::move 来将参数转化为右值
template<class T> |
编写测试程序如下
struct Foo{ |
分析这段代码, 我们可以发现在 main() 内部并没有构造函数的调用, 而是在调用 swap() 函数的时候调用了 Foo 的三种构造函数(之一)和两种赋值函数
对于语句 T tmp(std::move(a));, 对于 Foo 类型来说, 在它的三种构造函数中, 默认构造函数不接受参数, 因此被 pass, 对于下面两个构造函数, 两者都是可以接受的, 但是右值引用更优, 所以编译器会选择右值引用
右值引用可以绑定给 const 左值引用
对于接下来两个赋值语句, 类似的是, 赋值符号右边的右值虽然可以绑定给 const 左值引用, 但是编译器依旧是会选择更加优秀的右值引用来实现移动语义
右值引用本身就是左值
运行程序
void foo(int&& x){ |
对于 4 个函数的调用:
- 由于 1 是一个 prvalue, 只能绑定在 && 上, 因此自然而然的调用了第一个重载
- 自然而然的, i 和 lr 都是 lvalue, 也只能绑定在 & 上, 所以做了第二个重载
- 有趣的是, 作为 && 的 rr, 却绑定在了 & 上了
右值引用本身是一个左值!
根据之前的理解, 有名字的东西就是左值, 那右值引用很明显是有自己的 名字 的, 所以虽然我们叫他是右值引用, 实际上在编译器眼里他早就是一个纯正的左值了
那么 C++ 为什么要这么设计呢?
回到移动语义之初, 当我们书写 x = foo(); 这样的语句的时候, 我们是明确知道使用移动语义而不是拷贝构造更优秀且不会出错的, 但如果我们将右值引用视作右值
考虑函数
template<typename T> |
这个函数接收一个 && x 作为参数, 在我们的假设中, x 被视为右值, 这个构造就会被视作移动语义, x 所表征的内存就在不知不觉间被破坏了!
因此, && 会被视作 &, 以避免上述情况的意外发生
引用限定符
C++11 中引入了引用限定符对非静态成员函数做修饰, 用来根据调用者的值的类型来选择调用不同的重载
struct S{ |
当然, 引用限定符不会对 this 产生任何影响, 只是影响对重载的解释
移动构造运算符与移动赋值函数
SMFs
- default constructor
- destructor
- copy constructor
- move constructor (C++11)
- copy assignment operator
- move assignment operator (C++11)
如果类有自定义的拷贝构造, 拷贝赋值或析构函数三者中的一个, 那么这个类就不会隐式定义移动构造函数和移动赋值;
因此, 假如希望实现移动语义, 需要定义这五个函数





