C++ | 继承
这是 C++ 网课学习笔记
继承与 hiding
回顾之前给出的代码示例
class Shape { // 基类 Shape |
在这个实例里面, 我们认为 Circle 和 Rectangle 都是抽象类 Shape 的子类, 都有一些相同的成员, 也有一些独有的成员
实际上, 继承有两种理解方式
- 我们有很多的类, 但是我们可以抽象出他们的共同点, 利用共同点定义抽象父类, 做到代码复用
- 另一种理解方式是, 我们先有了一个父类, 再由父类派生出很多的子类, 继承自父类
一个类是否需要继承另一个类, 是需求决定的, 例如正方形在数学上肯定是长方形的子类, 但是在实际代码开发中, 是否一定要让正方形继承自长方形, 是一件有待商榷的事情
例如长方形由 width 和 height 两个成员, 而正方形应当只有边长一个成员
所以, 继承与否要考虑实际场景
类的布局
考虑 Circle 类对 Shape 类的继承
我们都知道, 如果一个子类是继承自某一个基类, 那么只要是基类有的东西, 子类一定也有
包括基类私有的成员, 这类成员会被继承, 但是无法被子类访问
这样的事情同样会发生在成员函数上
我们知道, 成员函数实际上是不占有内存空间的, 因此 C++ (准确来说是各类 C++ 编译器) 采取了另外一种特殊的方法保存了这些函数
既然如此, 那么我们分析一个 Shape 类, 其实对于 Shape 类来说, 他所保存的并不包含诸如 prepare(), finalize() 等函数的实际实现, 而仅仅保存了 center 一个成员变量. 更进一步的, 除了一些非静态的成员变量, 其他的成员均不会在一个类中占用位置
同样的, 继承自 Shape 的 Circle 也不会保存成员函数的具体实现, 而仅保存了继承自基类的 center 和独有的 radius
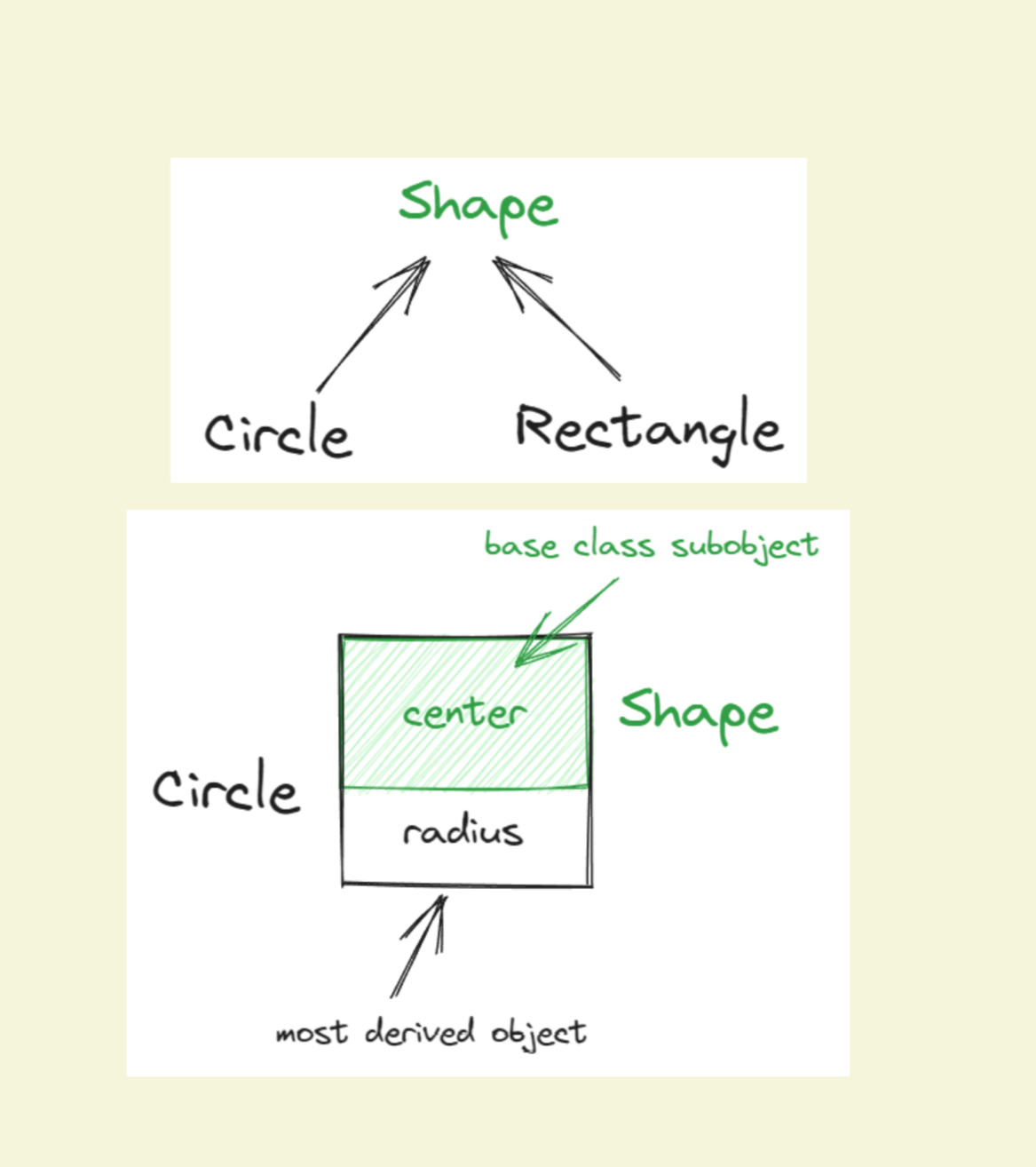
- base class object: 由于继承产生的成员
- most derived object: 派生类独有的成员
了解了构造与析构之后, 我们可能会把上述代码改写成如下形式:
class Shape { // 基类 Shape |
与之前不同的主要是我们加入了构造函数
Shape(int x, int y) : center(x, y) {} |
其中后面两个构造函数中的 Shape(x, y) 都是必要的, 假如缺失就会尝试调用 Shape 的默认无参构造函数, 然而 Shape 并没有无参构造函数
派生类的构造顺序
以下面的程序为例, 我们讨论派生类的构造顺序
struct Base { |
对于派生类, 构造派生类时, 会先构造基类, 在构造派生类
当 main() 结束时, 会按照构造顺序的反顺序依次析构, 析构派生类时, 会先析构派生类, 在析构基类
封装
我们刚刚其实已经提到过封装这个概念
- 将数组组合
- 将函数与之捆绑
- 加以访问控制
在 C 语言中, 我们构造 struct 和与之相关的一系列函数; 而在 C++ 中, 我们用 class 来替代封装的不够严谨的 struct
类在其中扮演的是一个作用域的角色
隐藏
int a = 1; |
这是一个经典的函数, 按照我们以前的理解, 当我们在 foo() 内部重新定义 a, 那么全局变量 a 就会被覆盖, 所以 a = 2; 的操作就改变不了全局变量的值了
因此我们在 foo() 中定义的 a 的作用域就是从定义的语句开始, 直到 foo() 结束
这种类似的覆盖, 在类中也存在
考虑下面两段代码
class Base { |
class Base { |
假如我们执行 Derived d; 考虑语句 d.a 的具体访问
- 对于前者, 访问的应该是 Base 的 a
- 对于后者, 访问的应该是 Derived 的 a
当然, 虽然派生类也有一个 a, 但是不代表基类的 a 就被覆盖了
struct Base { |
通过作用域分解运算符 :: 的显式声明, 我们可以直接告诉编译器: 我们要访问被隐藏的成员
当然这并不是一个好习惯, 我们不应该在基类和派生类中定义名字一模一样的成员
对于成员函数, 情况有一些些不一样
|
对于 pd->f(2.3) 这个访问, 我们想当然就能理解, 他一定访问了派生类的成员函数; 然而 pd->f(2) 却不一样, 并没有访问基类的函数, 而依然访问了派生类
实际上, 当我们没有指定作用域的时候, pd->f(2) 还是会优先访问基类, 访问的时候发现存在 2(int) 向 2(double) 的隐式转换可以满足条件, 于是就选择通过隐式转换调用派生类的函数
上面的写法是不好的, 因为很可能造成误解, 认为这是个重载, 实际上是个隐藏哦
当然, 假如非要这么做, 可以把派生类做如下改动
class D : public B { |
using B::f; 会告诉编译器在派生类寻找 f() 的时候考虑基类的 f()
当然, 这样代码依然是很低级的
访问控制
之前提到过的访问控制分为两种
- public 公开
- private 私有: 类外(包括子类)不能访问 private 成员, 除非声明为 friend
class Base { |
但是按照我们朴素的价值观来说, 派生类理应想必其他类, 与基类有更亲♂密的关系, 派生类应当可以访问更多的东西
受保护的成员 protected
C++ 引入了 protected
class Base { |
protected 和 private 继承
这些东西用的比较少, 没有必要深究
class Base { |
需要注意的是, 访问权限控制符控制的是访问权, 而不是可见性, 例如
int a; |
按照之前的理解, 由于作用域的覆盖性, 执行 a = 1; 时, 会向上寻找到基类的 a, 但是这个 a 是私有的, 不允许被访问, 编译器就会报错, 而不是再向上找到全局变量 a
这说明, 派生类是可以发现基类的私有成员的(知道私有成员存在或不存在), 但是没有权限访问这个私有成员
多继承与虚继承
C++ 支持继承的嵌套和多继承
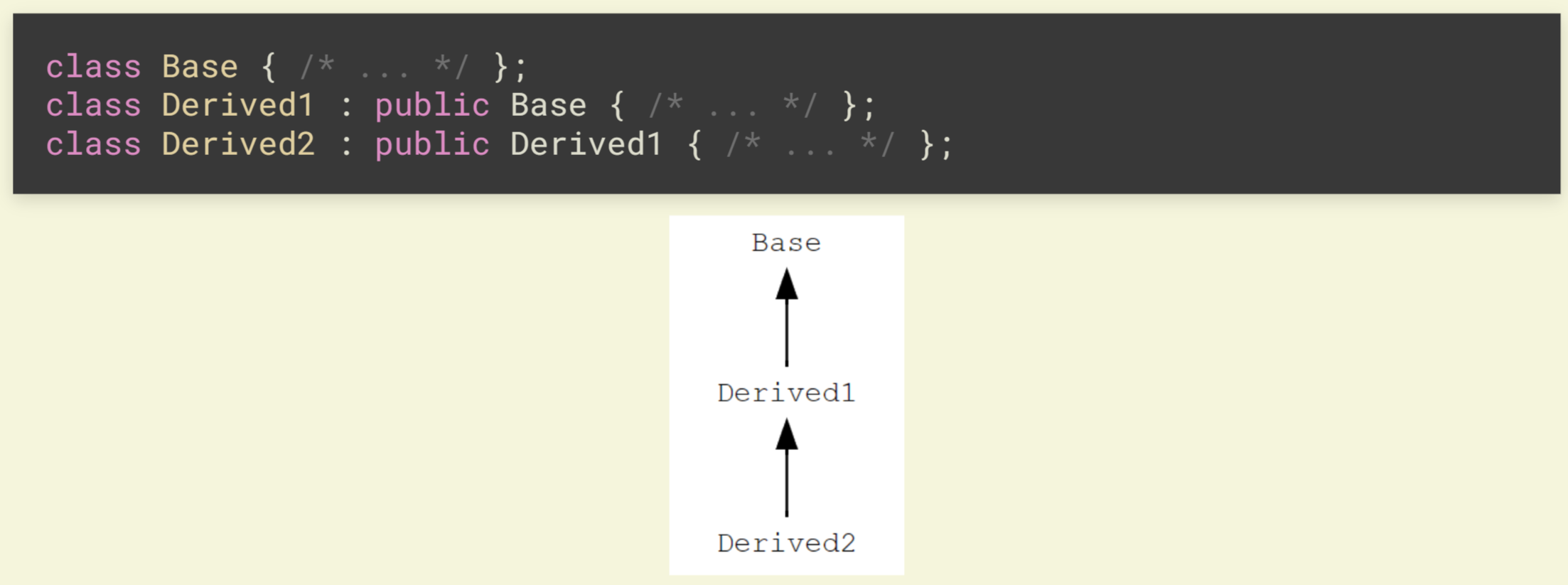
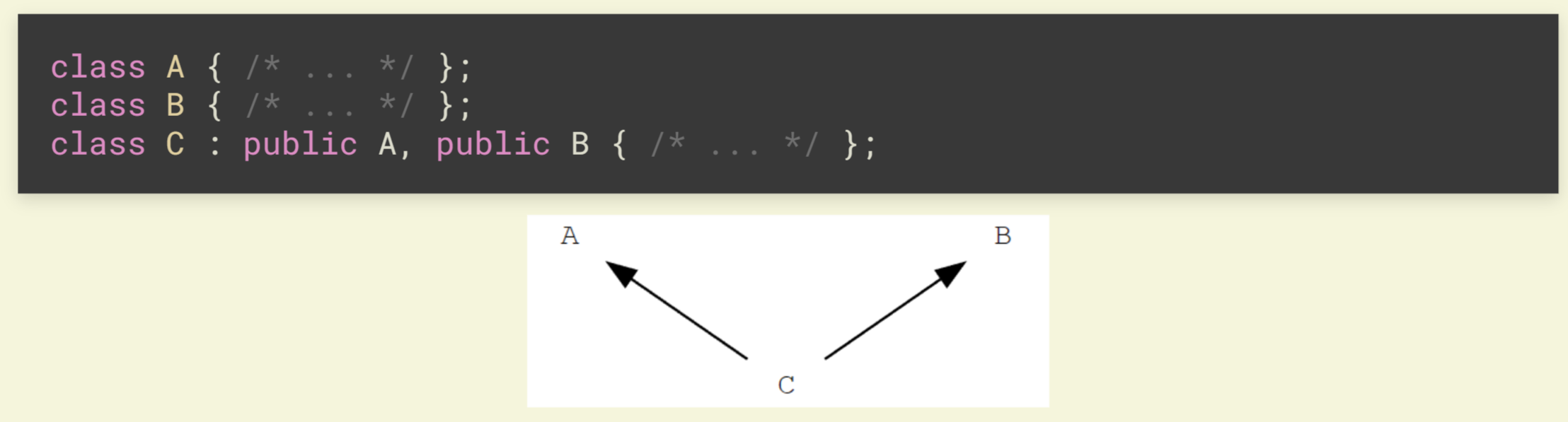
在多继承的情况下, 假如 A 和 B 均有一个名字为 x 的成员, 在 C 中访问 x 就会编译错误, 需要使用 A::x 或 B::x 进行限定
一些特殊的继承方式
还有一些特殊情况
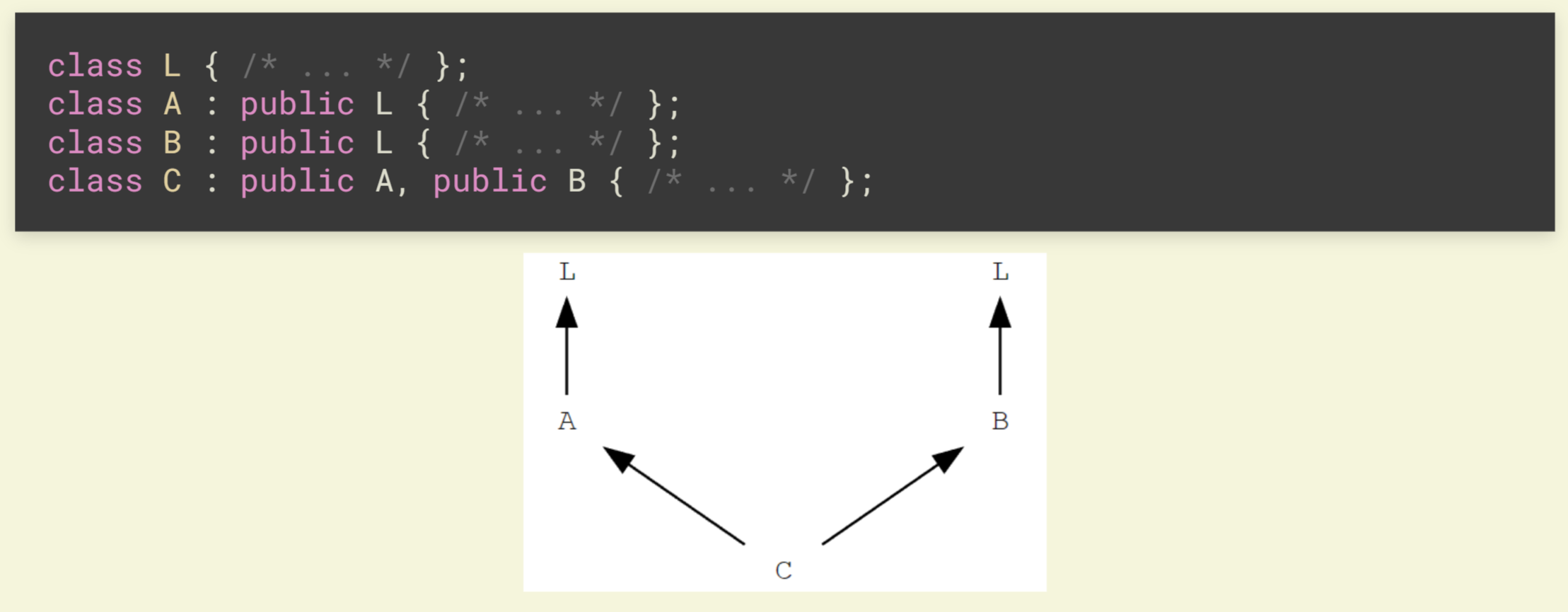
这时候, C 里面就会有两个 L 的子对象
有意思的是, 这样的操作, C++ 是允许的, 这时为了避免歧义, 一定要显式声明 A::L::x / B::L::x
有的时候我们不希望有这样别扭的继承方式, 我们只想要下图所示的继承拓扑结构(显然这样很符合直觉)
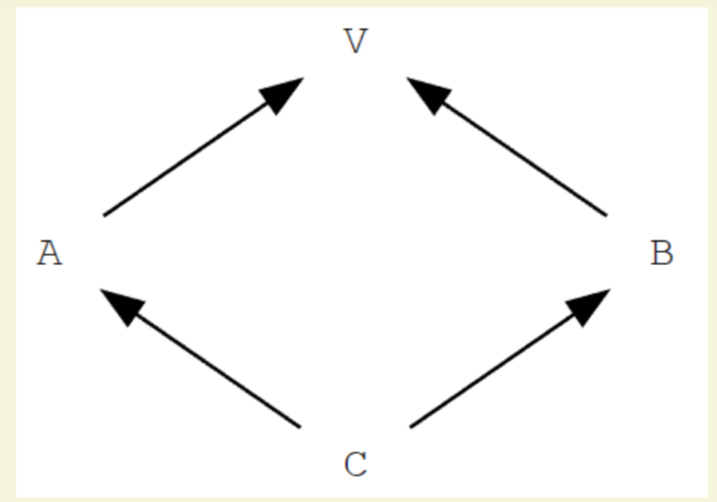
C++ 引入了虚继承解决这个问题
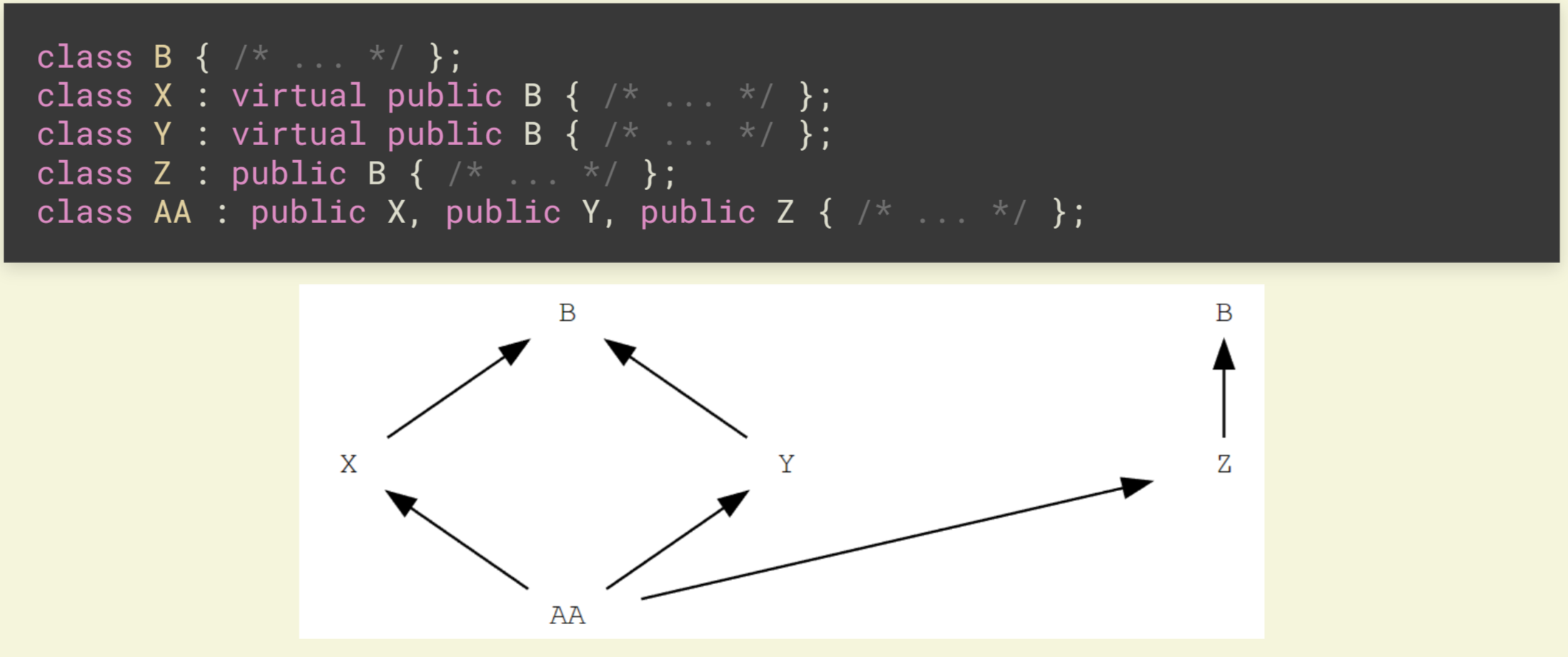
class V { /* ... */ }; |
这样的继承方式保证了在 C 中仅有一份 V
不做展开
虚继承可以和非虚继承同时存在(不要再套娃了啊喂)
类的初始化顺序
- 首先将虚基类 virtual base classes 按深度优先的顺序构造,同深度中则按 base-specifier list 从左到右的顺序初始化
- 然后,所有的直接基类 direct base 按照 base-specifier list 从左到右的顺序初始化
- 然后,将所有的非静态数据成员 non-static data member 按照其在类定义中声明的顺序初始化
- 最后,运行构造函数的函数体
类的析构顺序与上述描述相反
向上转型与对象切割 object slicing
Shape * pc = new Circle(0, 0, 1); // OK |
一个很基础的逻辑是, 派生类包含了基类
所以我们让一个基类的指针指向派生类对象, 是一个合理的操作, 从逻辑角度上看, 一个基类指针指向派生类对象, 可以理解为指针只指向派生类中的基类成员
同理, 派生类也可以绑定在基类的引用上
考虑派生类向基类的初始化和赋值
Shape s = c; |
当我们执行初始化语句的时候, 实际上调用了基类的默认拷贝构造函数 Shape::Shape(const Shape &);, 由于派生类对象可以绑定在基类的左值引用上面, 所以这个操作是完全合法的, 其进行的具体操作无外乎申请一片内存, 依次把对应的成员变量赋值上去
赋值语句就好理解了, 实际上调用了 Shape& Shape::operator=(const Shape &);, 原因同上
上述操作我们称之为对象切割 object slicing, 很形象的概括了这个操作 切割 下对象的一部分, 用来初始化另外一个的行为
因此, 在下面的程序中
class B { |
我们删除了原有的默认拷贝构造和拷贝赋值, 对象切割就失效了
向上转型依然可以
标准转换
调整或变换
- 数组向指针转换: void f(int *); int a[10]; f(a);
- 限定性转换: void f(const int *); int *p; f(p);
提升
- 整型提升: void f(int); char c; f(c);
- 浮点型提示: void f(double); float x; f(x);
数值转换
- 整型转换: void f(int); long long l; f(l);
- 浮点型转换: void f(float); double x; f(x);
- 浮点型向整型转换: void f(int); double x; f(x);
- 指针转换: T * p = nullptr; void * p2 = p;
- 向上转型: Base * pb = &derived;
- 布尔转换: bool b1 = i, b2 = p, b3 = x;
虚函数
virtual
virtual 关键字说明一个非静态成员函数是一个虚函数
- 虚函数的行为可以被派生类重写 override (区别于重载 overload )
- 如果基类有虚函数
Base::vf,子类有一个名字, 参数列表, 是否是 const, 允许左值或右值的调用权限这几个属性都相同的函数Derived::vf, 则称后者重写了前者
struct Base { |
举个栗子
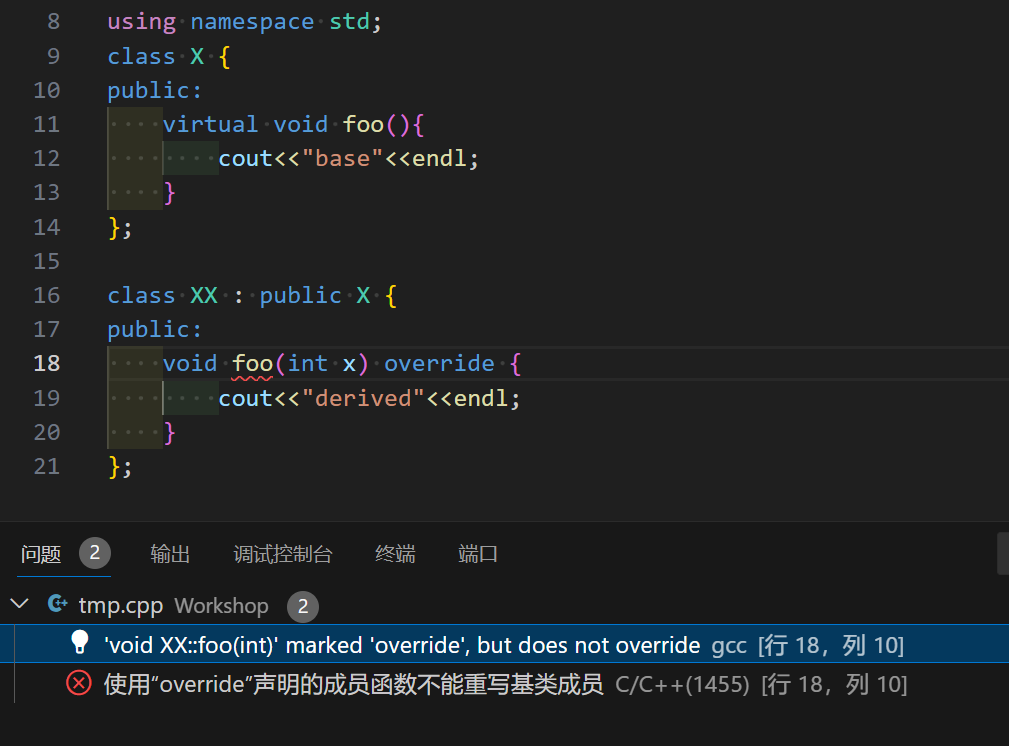
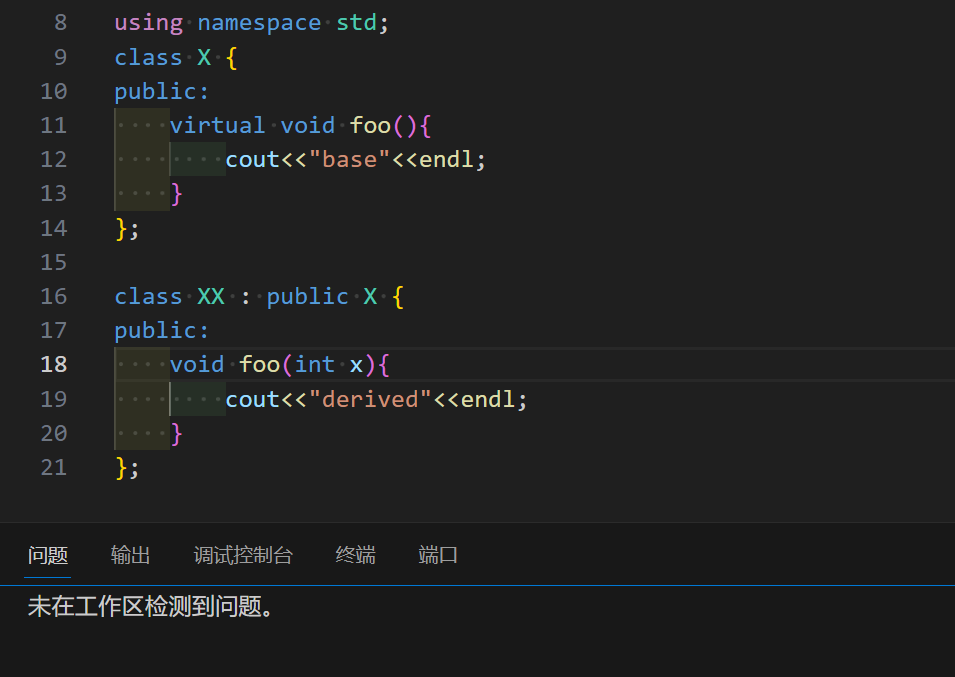
如图所见, 同样是错误的隐藏了基类的 foo() 函数, override 关键字可以帮助我们检查意外的隐藏
声明或继承了虚函数的类称为多态类
虚函数调用 virtual function call
对虚函数的调用称为 virtual call 或者 virtual function call,它会使用调用对象的实际类型中的 the final overrider
struct Base { |
值得注意的是, pb2 虽然是 Base* 类型, 但是实际上它指向了一个 Derived&, 所以调用了派生类的虚函数; 类似的的 rb2, 虽然是 Base& 类型, 但是实际上绑定了一个 Derived, 所以也调用了派生类的虚函数
作为对比, 我们去掉 virtual 和 override 关键字
struct Base { |
可以发现, 去掉后的两个 print() 变成了简单的重载, 因此会按照调用者的静态类型调用对应的重载
应用
作为例子, 我们考虑如下程序
class Shape { // 基类 Shape |
首先是一个语法点: virtual T foo() = 0; 是纯虚函数, 意思是要求所有派生类都实现这个虚函数
其次观察 drawAll() 函数, 它接受一个元素类型为 Shape* 的 vector, 当然根据我们之前关于向上转型的讨论可以知道, 一个类型为 Shape* 的指针是可以指向其派生类对象的, 作为栗子, 这里的 Shape* 可以指向 Circle / Rectangle
接下来观察函数体, 我们发现 draw() 并不是一个虚函数, 因此对于任意 p, 这个语句都会区执行 Shape 的 draw(); 调用 draw() 时, 我们发现 prepare() 和 finalize() 都不是虚函数, 直接调用, 而 do_draw() 是一个虚函数, 这时会发生虚调用, 再根据对象的实际类型调用对应的重写
纯虚函数和抽象类
纯虚函数不必有实现
一个存在有纯虚函数的类, 被叫做抽象类 abstract class
- 这里的纯虚函数指的是没有被完整重写的虚函数
抽象类不允许用于声明对象或数据成员
- 可以作为基类的底对象
- 不能作为参数、返回值和转换的目标类型
- 可以有抽象类的指针或者引用
例如
struct A{ |
纯虚函数可以有自己的实现, 在某些时候是有道理的, 例如需要一段功能在所有虚函数的重写上都至少要实现时
要求派生类必须重写自己和有自己的实现以提高代码的复用率并不矛盾
final
C++ 11 引入了 final 以避免一个类或虚函数不能被继承或重写
class Base final {}; |
struct Base { |
final 并不是 C++11 的保留字, 你可以写出 int final = 8; 的同时让其正常生效
虚表
刚才我们讨论的所有东西都是 C++ 标准委员会规定的 “虚函数应该应该怎么样”, 然而他们没有规定虚函数的具体实现方式
不过, 虚函数通常使用虚函数表 virtual table 实现
例如我们有这么一个基类, 他有 5 个虚函数
class Base { |
编译器会为每一个多态类创造一个静态的虚表(注意下面是伪代码)
FunctionPtr Base::__vtable[5] = { |
实际编写代码时, 请不要使用诸如 __vtable 之类, 由两个下划线开头的, 预留给编译器的变量名, 否则很有可能和编译器撞上
对于多态类, 编译器会自动增加一个成员变量指向这个虚表, 并在构造时初始化
class Base { |
假如有一个派生类继承了基类, 重写了前三个虚函数
class Der : public Base { |
编译器就会为派生类, 按照基类生成一个虚表, 并更新部分指针为重写后的函数指针(保留没有重写的虚函数)
FunctionPtr Der::__vtable[5] = { |
假如我们做出如下调用
void mycode(Base* p) { |
编译器会解释为
void mycode(Base* p) { |
然后找到虚表 Base::__vtable[3] 所指向的函数
虚函数的开销
虚函数增加了预测的成本
具体的开销取决于虚函数的开销与程序的开销的比较
实际上, 模板就是静态的虚表, 虚表就是动态的模板, 两者都是多态的实现
前者消耗编译时间以获得更快的运行效率; 后者消耗运行时间以获得更快的编译效率
一般我们认为模板会更加高效





